Asking for more machines, memory and cores is always a valid idea, but your CFO may not agree and may decline your request.
"Know Your Data"
As Demi Ben Ari says: "know your data" is the answer.
You must understand your business needs to get more from your cluster.
By understading your needs you will be able to run more tasks faster.
Moreover, if you utilize cloud computing resources such as AWS, better understanding will let you select the right type of instances and getting more for same money (or even less as we will see next)
What can be controlled?
In this post, I will focus on YARN based clusters, but concepts can be applied to Mesos and stand alone clusters as well. Some more information can be found as well at Cloudera post.
How Many Nodes Do I Have?
Take a look at the number of servers installed w/ NodeManagers. This is the number of nodes you can spin (in this case we actually have 4, although there are total 8 YARN clients installed).
A node is an actual physical or virtual server (depends on your environment)

Define YARN Limitations:
yarn.nodemanager.resource.memory-mb:
Total memory on a single node used by all executors
(NodeMemInGB - 1)*1024
yarn.nodemanager.resource.cpu-vcores:
Total cores on a single node used by all executors
(NodeCores - 1)
Define Spark Executors Balancing
--executor-cores / spark.executor.cores: The number of cores per executor (number of tasks executor can run).
--executor-memory / spark.executor.memory:
The executor memory (Actual upper limit is 64GB due to GC).
To which spark.yarn.executor.memoryOverhead will be added (default to max(384, .07 * spark.executor.memory))
Application master also requires default of 1GB and 1 core that runs on the driver and therefore we'll always decrease a single core and 1GB in our calculations. These can be controlled by the following parameters:
--driver-memory
--driver-cores
--num-executors / spark.executor.instances:
The number of executors for a single job
Can be avoided using spark.dynamicAllocation.enabled
The massive interactive small data scenario
This is not a common scenario, but some people may want to run large number of tasks on relative small data.
This might not be the best practice for a Big Data, but it will provide us a good understanding of Spark cluster sizing based on this edge case.
We'll start w/ a default 4 nodes m4.xlarge 4 vCores, 16GB (on demand cost $0.239/hour of $717/month)
1. First we will maximize the resources for any given node:
yarn.nodemanager.resource.memory-mb: (16-1)*1024 = 15,360MB
  |
| Memory Before and After |
yarn.nodemanager.resource.cpu-vcores: (4-1) = 3 vCores
  |
| CPU Before and after |
|
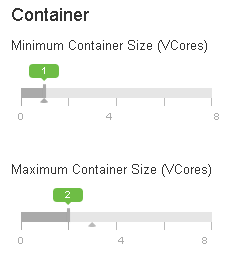

spark.executor.cores: 1
spark.executor.memory: (16-1)*(1-0.07)/3 = 4
spark.executor.instances: 3/1*4nodes = 12 executors
The Results
After finishing configuration, we enabled 12 tasks that run 24x7 using a manual schedualer written in our lab.
As you can see number actually fit our design: CPU jumps and hits the 100%, while cluster remain stable and not crushes.
 |
| The cluster utliliuzation jump after conifiguration to 12 executors and running 8 tasks every minute |
 |
| The cluster utilization hits 100% CPU w/ 11 tasks every minute |
Optimizing the Instance Types
Since our bottleneck is CPU vCores, by knowing our data we should seek another type of AWS instance. c3.2xlarge is an acutal match as the C3/4 series is optimized to provide more CPU and cores for less money (a c4.2xlarge instance has w/ 8 vCores and 15GB at $0.419/hour, so for $629/month we'll get 2 c4.2xlarge nodes).
1. First we will maximize the resources for any given node:
yarn.nodemanager.resource.memory-mb: (15-1)*1024 = 14,336MB
yarn.nodemanager.resource.cpu-vcores: (8-1) = 7 vCores
2. Then we will maximize the number of executors, by minimize the number of cores per executor to 1
spark.executor.cores: 1
spark.executor.memory: (15-1)*(1-0.07)/7 = 1
spark.executor.instances: 7/1*2nodes = 14 executors
Bottom Line
With some little tweeking, we could get 17% more exectores for 12% less money, or bottom line of 33% more value/money!
Keep Performing,
Moshe Kaplan
P.S You should explore more ways to save money on this kind of architrecture by utilizing:
- Reserve instacnes
- Spot instances

